Reducing Translation Errors in Healthcare: Comparing Today's Leading Approaches
7 days ago 51

A patient arrives at a hospital speaking only Somali. She describes her symptoms. The resident, working from a machine-translated triage note, reads the word "intoxicated" where the correct translation should have been "poisoned." The difference between those two words shapes every clinical decision that follows.
Language barriers are not a peripheral concern in modern healthcare. According to StatPearls' review of medical error reduction and prevention, communication failures rank among the leading causes of preventable medical errors in hospital settings. The WHO Global Patient Safety Report 2024 found that more than one in ten patients globally experience harm during medical care, with a substantial proportion of those incidents tracing back to communication failure.
Translation is a specific and particularly high-stakes subset of that communication problem. The question that healthcare administrators, clinicians, and policy researchers are now confronting is no longer "should we translate?" It is: "which approach produces the fewest errors, at the scale and speed that clinical care demands?"
This article compares the four main translation approaches used in healthcare today, with data on error rates, availability, cost, and risk profile.
Healthcare systems currently rely on four translation methods, sometimes in combination, depending on budget, urgency, and availability.
Live professional interpretation, delivered in-person, via telephone, or via video remote interpreting (VRI), remains the gold standard for real-time clinical encounters. Interpreters trained in medical terminology can capture nuance, tone, and non-verbal communication in ways no automated system can replicate. The critical limitation is availability: professional medical interpreters are expensive, difficult to schedule in emergencies, and largely absent for low-density languages.
For written medical content, discharge instructions, consent forms, and clinical records, professional human translators are the traditional standard. They apply subject-matter expertise, cultural competency, and legal awareness to produce certified translations. The trade-off is time and cost: professional translation for complex medical documents can take days and accumulate significant per-word fees at scale.
Consumer-grade AI translation, using a single neural machine translation model such as Google Translate or DeepL, has expanded healthcare access to translation at near-zero marginal cost. However, the clinical evidence is not uniformly positive. A peer-reviewed study published in PMC evaluating
commercially available machine translation applications for clinical communication found that all three tested AI systems were inferior to professional human interpretation, with significant variation in accuracy across languages.
The most recent development in clinical translation technology is architectures that run multiple AI models simultaneously and derive a consensus output from majority agreement among them, rather than trusting any single model. This approach addresses the fundamental problem with single-model AI in healthcare: any one model can hallucinate, misfire on terminology, or produce structurally correct but clinically incorrect renderings.
As AI's expanding role in clinical communication has accelerated, this consensus architecture has emerged as the mechanism that allows healthcare providers to capture AI's scale and speed without inheriting its single-model error risk.
The table below benchmarks each approach across the criteria most relevant to clinical and administrative decision-makers in healthcare settings.
| Criteria | Human Interpreter | Human Translator | Single-Model AI | Multi-Model AI(Consensus) |
| Critical Error Rate | Very Low | Low | 10-18% | Under 2% |
| Turnaround Speed | Real-time | Hours/Days | Instant | Instant |
| Cost | High | Medium-High | Low | Low-Medium |
| Scalability | Low | Low | High | High |
| Terminology Consistency | High | High | ~78% | ~96% |
| HIPAA/Compliance Ready | Yes | Yes | Varies | Yes (with verification) |
| Handles Rare Languages | Limited | Limited | Moderate | 330+ Languages |
| Human Verification Option | Built-in | Built-in | Add-on only | Integrated |
| 24/7 Availability | No | No | Yes | Yes |
| Hallucination Risk | Minimal | Minimal | 10-18% | Under 2% |
Table 1: Healthcare Translation Approach Comparison (2026). Error rate data: Intento State of Translation Automation 2025; PMC clinical studies.
Error rates in healthcare translation are not a minor quality metric. They are a patient safety metric. Below is a visualization of critical error rates (errors with potential for clinical harm) across the four translation approaches, based on published clinical research and industry benchmark data.
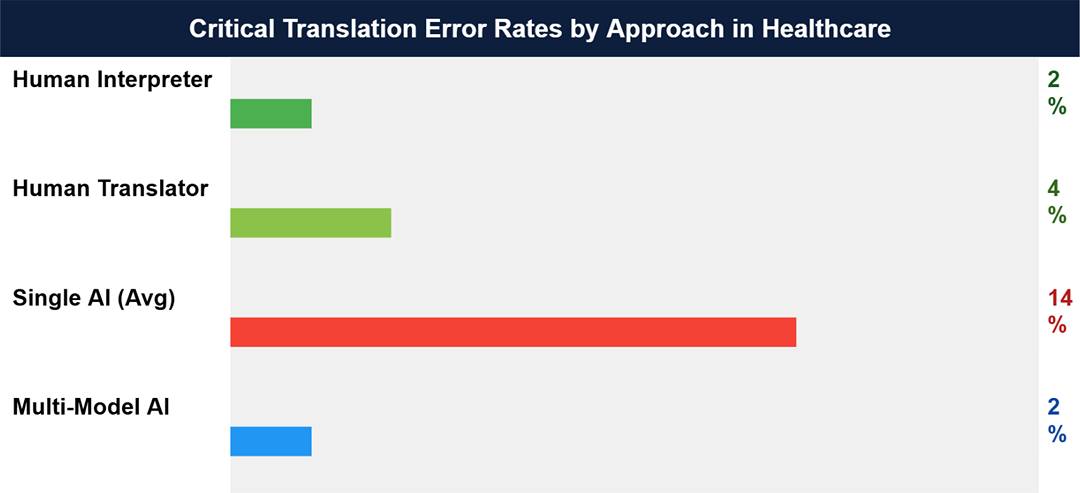
Figure 1: Critical translation error rates by approach. Sources: PMC peer-reviewed clinical studies (2023-2024); Intento State of Translation Automation 2025; Percentages represent critical errors with potential for clinical harm.
The range for single-model AI (10-18%) is not a worst-case scenario. It is the average performance range drawn from industry data synthesized from Intento and WMT24 benchmark testing of leading LLMs on translation tasks. A comparative PMC study on AI versus professional translation of discharge instructions found that AI performed near-professional levels for Spanish and English-to-Chinese translation, but gaps widened significantly for less common languages, where infrastructure for training and evaluation is thin.
The practical implication for a hospital system serving a multilingual population is this: a 10-18% critical error rate in translation means that between 1 in 10 and nearly 1 in 5 translated clinical documents contains an error with the potential to influence clinical decision-making negatively.
The error problem with single-model AI in healthcare is structural, not incidental. A large language model producing a translation operates as a probabilistic system: it generates the most likely output given its training data. In rare languages, low-resource language pairs, or domain-specific terminology (oncology terms, rare pharmacological names, surgical procedures), the model's training data is thin, and its confidence is statistically unjustified.
The multi-model approach directly addresses this structural flaw. By running a translation through multiple AI models simultaneously and requiring majority agreement before delivering an output, the architecture discards outlier renderings before they reach a clinician. A hallucinated drug dosage that one model produces but 21 others do not will not appear in the output.
MachineTranslation.com, an AI translator developed by Tomedes, applies this mechanism at scale. Its SMART system runs text through 22 AI models simultaneously, including ChatGPT, Claude, Gemini, DeepL, and 18 others, and returns only the translation the majority agree on. Internal benchmark data shows this reduces critical translation errors to under 2% from the 10-18% range typical of single-model systems. The platform also maintains terminology consistency at a rate exceeding 96% across multi-document workflows, compared to approximately 78% for single-model outputs at equivalent volume.
For healthcare contexts specifically, MachineTranslation.com includes a Human Verification layer: when a translation requires certified accuracy, a professional human reviewer is available within the same platform, without switching vendors or workflows. This makes the platform usable for both high-volume administrative content, where AI consensus is sufficient, and for legal consent forms or critical discharge instructions, where human verification delivers a 100% accuracy guarantee.
|
Clinical Use Case A hospital system processing discharge instructions in 12 languages daily can use the AI consensus mechanism for standard post-visit summaries and escalate to human verification for post-surgical instructions, consent forms, or rare-language cases, all within a single workflow. The consensus layer reduces review burden by filtering out the bulk of error-prone outputs before any human sees them. |
No single translation approach is optimal for every healthcare scenario. The decision should be driven by clinical risk, language availability, volume, and urgency. The matrix below provides a decision framework.
| Scenario | Best Approach | Why | Risk if Wrong Approach |
| Live patient consultation | Human Interpreter | Real-time, context-aware | Missed diagnosis |
| Discharge instructions (common lang) | Multi-Model AI + Human Verification | Speed + accuracy, verified | Medication non-adherence |
| Rare language documents | Multi-Model AI (330+ languages) | Human coverage gaps | No translation at all |
| Clinical trial documentation | Human Translator | Regulatory compliance critical | Regulatory failure |
| High-volume multilingual records | Multi-Model AI | Scale without quality loss | Errors compound at scale |
| Legal consent forms | Human Translator + Review | Liability requires certainty |
Legal/ethical exposure |
Table 2: Translation approach selection framework for healthcare settings. Scenario risk levels reflect clinical and legal exposure, not administrative preference.
The practical pattern this matrix reveals is that human interpreters remain irreplaceable for synchronous clinical encounters, while multi-model AI has become the strongest option for asynchronous, document-based, or high-volume translation needs. The key advance is that AI-driven efficiency gains in healthcare settings now come with a built-in verification architecture that removes the need to choose between speed and safety.
Every translation approach discussed in this article has a failure mode. Human interpreters are unavailable at 3am for a rare-language emergency. Human translators take days when a patient needs to understand their post-surgical instructions before discharge. Single-model AI produces clinically incorrect outputs at a rate that makes it unsuitable as a standalone solution for any content where accuracy carries direct patient risk.
The multi-model consensus approach reduces but does not eliminate that risk at the AI layer. What closes the gap is the verification layer on top: the option to escalate any translation to a qualified human reviewer when the stakes require certainty rather than probability.
The direction the field is moving is clear: away from single-model AI deployed in isolation, and toward layered systems where AI handles volume and speed, consensus handles accuracy, and human verification provides final sign-off for the highest-risk content. Healthcare systems that map their translation workflows to this layered model are building translation infrastructure that matches their clinical obligation: do no harm, including in translation.
Comments (0)